How Prezi switched data centers on the fly

The pit crew can change the tires on a racecar in 12–14 seconds[1]. That’s insanely fast compared to the 29 minutes, bruised fingers, and oil stained pants that it took me to do the same thing with our family car, but the difference is quantitative, not qualitative. Every single tire change on every car from the T-model to the Thunderbird follows a similar process:
- The car must stop.
- The old tires are removed.
- New tires are attached.
- The car may move again.
When we decided to move our infrastructure into the Amazon Web Services Elastic Compute Cloud (AWS EC2) at Prezi, we also needed to move one of our most valuable assets — presentation metadata. This includes information such as which user has access to which presentation and where the content of the presentation is stored.
The traditional process for database migration involves scheduled downtime during which a backup of the old database is used to populate the new DB. In our case, this would have meant none of our users could present with Prezi for at least a full day, something we didn’t want to put millions of people through. We needed to change the tire without stopping the car.
Beginnings
All successful startups initially create the “monorail”: one gigantic web-app which does it all, from serving web content to providing APIs and admin interfaces. Prezi is no exception. Our monorail was built in Python using the Django web framework and used MySQL to store state. All of this was running on rented physical hardware.

Even before we decided to move to AWS, we experienced the disadvantages of having a single service which serves extremely critical requests (“can user X view presentation Y”) as well as fluffier stuff (“show recommendations after the user has finished viewing a presentation”).
Any problem in the not-so-important part of the application brought down the whole thing. To isolate the most important endpoints, we separated out several critical components into stand-alone services, running as separate processes. One example was the presentation metadata service.

Note that running as separate processes gave us application-level isolation, but both services were using the same database. Indeed, they had to, as both applications manipulated the data therein.
The database remained a single point of failure for the time being, but it did not become a showstopper until we decided to move to EC2.
Having two separate services was a great first step, but it was just the beginning of the long and winding road towards AWS.
Moving: the naive approach
Using Amazon Web Services EC2 instances to run our internal services offered us the scalability we need. As long as all the critical requests were received by nodes in their cloud, we could easily provision more database or application servers and serve increased traffic without flinching. The monorail depended heavily on the complex setup we had for our rented hardware in the old datacenter, so it would have to stay put for the time being.
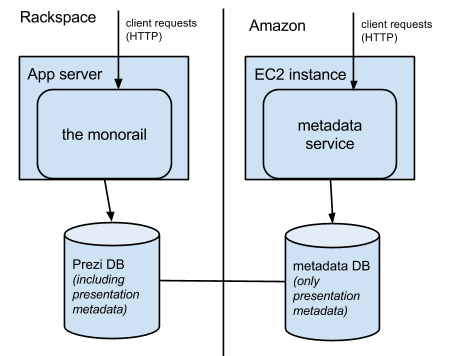
Our first approximation of the architecture is depicted above. The line connecting the two databases represents the fact that both of them would contain the presentation metadata. The two DBs would need to be in sync, eventually propagating changes from one database into the other.
It eventually became apparent that this naive approach would not work well in practice. For one, the physical distance between data centers means that there would be considerable lag in the replication of data. This would lead to strange inconsistencies like some endpoints returning objects not available from other endpoints (depending on whether the endpoint was served by the monorail or the metadata service).
Unfortunately replication lag was just the tip of the iceberg. We also had to worry about collisions, which happen when the two databases are simultaneously changed in divergent ways. In these cases replication stops and the conflict must be addressed manually before replication can be re-established. Perhaps we could replicate data between datacenters as a temporary measure, but this would be far too brittle to act as a long-term solution.
Clearly we would need a single database to house the metadata, but due to a number of issues, just connecting directly to the MySQL database from a different data center was not a workable solution.
Moving: Take 2
Since keeping two databases with the same data in sync proved to be a dead end, we were left with a solution without redundancy: everything except presentation metadata would remain at our old provider. The presentation metadata would be moved to EC2. Fortunately, the new presentation metadata DB could be implemented as a cluster of machines using Percona XtraDB server, so it would no longer be a single point of failure.
For this to work, the code in the monorail would need to be smart enough to make an API call over HTTP for presentation metadata, while using the direct SQL connection for everything else. The component responsible for this decision will be referred to as “switch logic”.
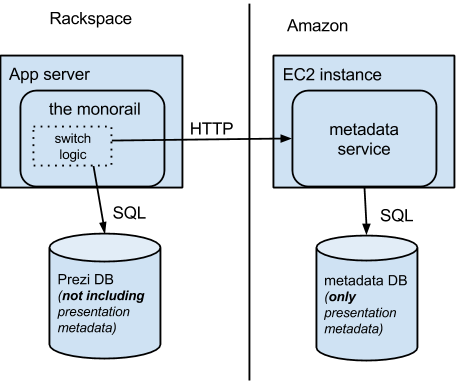
The monorail code reads and modifies presentation metadata in hundreds of places. It would have been practically impossible to replace all instances of direct access with this more complex switch logic in one commit.
Other teams were constantly changing code in the monorail and deploying new versions. We could not “stop the car” and work on a monorail 2.0 branch which would include the switch logic in the necessary places and deploy when we were finished.
Our only option was to swap out direct DB calls with the switch logic component piece by piece — naturally, without causing an outage.
Baby steps
The presentation metadata could only be moved to a separate database once the monorail was fully transitioned to using the switch logic for data access. We came up with the following plan:
Presentation metadata migration steps (version 1)
Status: The presentation metadata service and the monorail are separate processes, but they share the same database.
Step 1: Replace direct SQL queries with switch logic in the monorail.
Status: The monorail makes API requests to the presentation metadata service to access its data, but both services continue to share a database.
Step 2: Install the presentation metadata service in EC2, and redirect requests from the monorail to these instances.
Status: the move is complete, presentation metadata is stored in EC2, and accessed via API calls to the metadata service.
As the list of steps above shows, we had to make sure the monorail accessed presentation metadata exclusively through the switch logic before we could move any data. Until the switch logic rewrite was complete, the metadata service and the monorail would still share a database. The completion of Step 1 in the process outlined above leads to the following architecture.
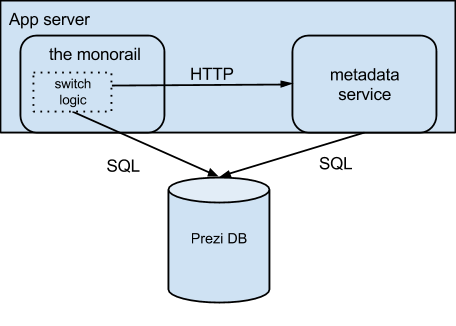
It took us more than three months to replace the monorail’s SQL queries with switch logic. At first glance, it seems safe to access presentation metadata directly in some places, while making API requests to the metadata service in others. They are using the same database after all. Unfortunately, this proved problematic for some rather common use cases. Consider the creation of new presentations:
- A method in the monorail starts a mysql transaction.
- Within the transaction, a row is inserted into the presentations table.
- In order to give the presentation’s owner permission to edit her content, an HTTP request is issued to the metadata service to add a new (presentation id, user_id) row to the permissions table.
- The metadata service does not find a presentation with the given presentation id, since the transaction has not been committed yet. The SQL Foreign Key constraint prevents the insert statement’s execution. The API request fails.
- When the transaction is committed, the owner is not given editing rights on their own presentation!
As a result, even though we had to introduce the switch logic into the monorail piece-by-piece, we could only turn on the API request method of accessing metadata when we were finished. Fortunately, we already had a system for “feature switches” which we used primarily for A/B testing. We could use a feature switch for turning on HTTP requests nearly simultaneously. This led us to the following process:
Presentation metadata migration steps (version 2)
Status: The presentation metadata service and the monorail are separate processes, but they share the same database.
Step 1: Replace direct SQL queries with switch logic in the monorail.
Status: The monorail continues to issue SQL queries directly, but it always consults the “switch logic” first.
Step 2: In the monorail, turn on the API call access mode instead of querying the database directly.
Status: The monorail makes API requests to the presentation metadata service to access its data, but both services continue to share a database
Step 3: Install the presentation metadata service in EC2, and redirect requests from the monorail to these instances.
Status: the move is complete, presentation metadata is stored in EC2, and accessed via API calls to the metadata service.
Database remote control
Initially, our monorail application used the Django ORM to access data stored in the SQL database. This made it easy to map database state to model class instances. The Django ORM translates a Python expression such as:
Presentation.objects.get(id=1)
into the SQL query needed to fetch the data, in this case,
SELECT title, description, … from presentations where id = 1
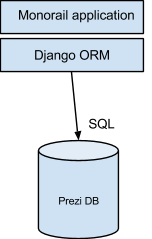
After introducing the switch logic, the Python calls for accessing presentation metadata had to be changed to something like:
RemotePresentationFactory().get(1)
The switch logic could choose between “backends”. The Django backend called into the ORM (in this case Presentation.objects.get(id=1)). The ORM then made a direct SQL query. We used this backend until our work on the monorail was complete, and all data access went through the switch logic. After we turned on the feature switch for API requests, the switch logic started using the Thrift backend for presentation metadata, our architecture looked more like this:

How we became a Thrift shop
There are an intimidatingly large number of RPC systems to choose from. We decided to go with Apache Thrift for the following reasons:
- It’s open source, and has a number of high-profile users (Facebook, Twitter, etc).
- The interface description language (IDL) is expressive and has familiar syntax.
- It supports all the languages we use at Prezi.
- It comes with multiple wire-formats, some optimized for debugging, others for minimizing traffic.
Creating Thrift interfaces starts with the Thrift file. The IDL defines methods that the server will offer clients. Methods often consume or return complex values that are also defined in the Thrift file. We realised early on that in most cases, a very limited set of operations is enough: we want to create, read, update and delete rows in database tables. In addition to these operations (commonly referred to as CRUD), we also needed a limited ability to search for records.
We created a tool to generate a Thrift file for each database table that contained presentation metadata. For a presentation table created with:
CREATE TABLE presentations ( id int, title varchar(1024), owner_id int);
The corresponding Thrift file would look similar to this (I left out the search method):
struct Presentation { 1: optional i64 id, 2: optional string title, 3: optional i64 owner_id
}service PresentationCRUD { Presentation create(1: Presentation presentation) Presentation read(1: i64 presentation_id) void update(1: Presentation presentation) void delete(1: i64 presentation_id)}
Based on this Thrift file, the Thrift compiler can generate Python client and server code. The Thrift backend of the switch logic acts as the Thrift client. For example, to delete the presentation with id 1 through an API request, the Thrift backend would run:
client = PresentationCRUD.Client(protocol)
client.delete(1)
In the code above, protocol refers to an object which determines the wire format used, the network address of the server, and many other parameters specific to the RPC request.
On the server side, we wrote a Thrift server which integrates with the Django framework, allowing us to use the same stack for executing Thrift requests as the one we use for REST APIs and web content.
Completing the move
Our next step was to launch instances in EC2 running the metadata service and the distributed database. As noted earlier, we knew that keeping two-way replication in sync between our old datacenter and EC2 would be a nightmare in the long term, but it was essential for the duration of the move. The actual switch happened when the monorail started making HTTP requests to the metadata service instances running in EC2. The final move procedure looked like this:
Presentation metadata migration steps (version 3)
Status: The presentation metadata service and the monorail are separate processes, but they share the same database.
Step 1: Replace direct SQL queries with switch logic in the monorail.
Status: The monorail continues to issue SQL queries directly, but it always consults the “switch logic” first.
Step 2: In the monorail, turn on the API call access mode instead of querying the database directly.
Status: The monorail makes API requests to the presentation metadata service to access its data, but both services continue to share a database
Step 3: Install the presentation metadata service in EC2 along with it’s database, and set up two-way replication between the databases in the two datacenters.
Status: At this point there is a fully functional metadata service in both our old datacenter and EC2. Either one can process requests. Database modifications issued in one DB will be replicated to the remote data center. The monorail is still using the local instance of the metadata service.
Step 4: Change the configuration of the monorail to issue API requests to the metadata service in EC2.
Status: Both the old datacenter and EC2 metadata services are fully functional and their databases are in sync. The API requests from the monorail are now going to EC2.
Step 5: Terminate the presentation metadata service at the old datacenter, break the replication between databases.
Status: the move is complete, presentation metadata is stored in EC2, and accessed by the monorail exclusively via API calls.
The two-way replication was necessary because Step 4 is not an atomic change: the monorail processes pick up the new configuration at nearly the same time, but there is a moment when the presentation metadata services in both datacenters receive requests from the monorail.
Conclusion
The separation of the presentation metadata service took us about two months. Preparation for the move took us another five. During the move we did have two unplanned outages, but they lasted only a few minutes each. Overall, the presentation metadata move was a success. We have since moved other services out of the monorail using the same playbook.
So don’t despair if it turns out you have to replace databases or switch data centers without a noticeable service interruption, but be prepared to spend some time getting ready for the move.

